-

I think it’s wonderful, really great to meet and be introduced. I just wanted to take a few seconds, as we weren’t able to catch you at IGF, to introduce myself and really just understand how you’re seeing the international conversation on generative AI and AI priorities come together.
-
You know, in your ministry there, any key milestones and priorities and really just understanding ways here at OpenAI on the international policy team can be helpful to you over time and just really wanted to start a conversation. So really glad to have a little bit of time with you. I know your schedule is so busy.
-
So thank you again, I’m James Hairston and I lead international policy at OpenAI. Been here going on about five months and really coordinate our work, across the international institutions and around the world. So just excited to have a bit of time with you today.
-

Great. And as communicated previously, we will not publish any of this recording, but we will make a transcript, we will co-edit before publishing. So feel free to remove any bits that you consider sensitive, including your questions. So, yeah, maybe the easiest way to start is to start with the motivation, right?
-
In my ministry, I’m in charge of the Ministry of Digital Affairs, which is about universal access, about participation, and fundamentally about collaborative diversity, about using digital technologies to push the boundaries of how collaborative we can be and how diverse can we include people who collaborate together. I had a lengthy conversation with Wojciech Zaremba of OpenAI on how to use that digital technology, specifically generative AI, to enhance deliberative democracy. And I mean, it’s published online, so I will not quote there, but it did eventually lead to the Democratic Input blog post from OpenAI. So that’s my core work.
-
And underneath my ministry, there’s administration for digital industries, which is for the progress part. So popularizing AI, especially edge AI, things that run on the edge, that protects the privacy and security, or investing in homomorphic encryption and zero-knowledge technologies that let, for example, OpenAI to retain the model weights, but for people to encrypt their queries when sending to you. That is another way to preserve privacy, split learning, split fine-tuning. That’s another way, right? So privacy-enhancing technologies for industrial progress, which makes full use of private data, but in a way that does not cause any privacy leak. That is the focus of our digital industries administration.
-
And finally, I’m also chair of the National Institute of Cyber Security and I also oversee the Administration for Cyber Security. As we all know, the information hazards, the synthetic information, the defeating of watermarking by open source models up to, I believe, 300 tokens now are completely paraphrased, needs a new thought on defending against information hazards. And so we work on provenance technologies, works on pervasive FIDO rollout, and many other things, zero trust architecture, assuming breach, to make sure that the upcoming election in January stays safe from generative AI attacks. But as you know, it’s not just synthetic images and video and text, but also living off the land cybercrime that can synthesize zero day on the target’s computer. It also poses a potential biohazard. And five other things that I’m sure you’re very acutely aware of.
-
So we’re also working on a certification and evaluation center to the end of the year to highlight upcoming threats. And Taiwan has good track record in that. As you know, during the three years of pandemic, we never locked down. People always can move from city to city. And the result is the best, or next to New Zealand, the world’s best in terms of counter-pandemic. And this relies on democratizing this rapid response and sensing system that allows people to work with epidemiologists with a ladder of expertise. And so the cybersecurity awareness, that’s also part of the cybersecurity institute.
-
So in short, participation, progress, and safety, this triangle is my job to increase the overlapping of these three values without making sacrifices or trade-off, because the time you start making trade-offs, you stop pushing the boundaries of how emerging technology can be used in service of democracy. I hope that answers your initial question.
-
Yeah, no, that’s really great, and such a helpful overview. And I’m curious, even for the Cyber Institute, are there plans for just sort of publications of sort of, whether it’s threats and the research around the attacks sort of over the coming months, and you guys just imagine that will be such an important contribution to the global security and safety conversation.
-
Yeah, definitely. I mean, the Global Engagement Center of the US works closely with Taiwan civil society and the broad cybersecurity ecosystem, and they just published a report about FIMI, foreign information manipulation and interference. And I’m sure that there’s many researchers in Taiwan around January for this particular topic and we’ll probably publish right afterwards.
-
Great, great. And I’m curious for reflections too, as you’re coming off of IGF and many of the discussions on sort of AI governance around the world, just how you see the conversation internationally playing out, your perspectives on what you’ve heard from the international institutions, the work on codes of conduct, concerns you have, opportunities you see there, just any sort of general reflections coming off of the discussions this week.
-
Yes, certainly. I mean, I’ve long argued for open red teaming for the frontier models, to basically adopt the cybersecurity mentality rather than just non-proliferation mentality, which is a very different metaphor for most of the things.
-
In cybersecurity, you assume breach, you assume there will be vulnerabilities, you assume that through open bug bounties, cyber drills, people working together, responsible disclosure, planning for buffering — the Anthropic idea of buffering for six times more vulnerabilities and so on safety margins. All this is risk management. But nuclear proliferation is a different metaphor. There’s a threshold of uranium concentration below which everybody gets to play, above which nobody gets to play essentially.
-
I’ve always pushed for the cybersecurity metaphor. And that requires something that is like the emergency response team, the CERT, the SOC, the ISAC, the post-release product incident response PSIRT, and so on, which I’m sure you’re already aware of. And I think this week I’m happy to hear that previously folks who don’t do open red teaming are now seriously considering or even about to agree on the values of open red teaming. I think this has, without naming names, real possibilities to flip open source models from the maverick of the family into, well, doing good things of the family, because then it democratizes community input into open red teaming. It allows people to work on not just safety, but also alignment in a democratic way.
-
And this is fundamentally what Alignment Assemblies is about, is the art of people in a community having a voice, even fine-tuning their LoRa that solves cultural misalignment issues like we heard about the anti-Muslim bias in the ChatGPT model and things like that. So that nothing about the community without the community. And when the community gets access to open source models, they have the means to correct such biases and also indirectly contributes to the cybersecurity awareness and directly contributes to safety.
-
I think that’s so important. I mean, and it speaks to why the work that you’ve done on alignment assemblies and, you know, sort of getting the democratic inputs is so powerful because I think building this community of practice around all of the risks, you know, short, medium and long-term. And I like that sort of recasting the metaphor as well. I think the work that we do to capacity build and bring more people, more civil society, more communities into this sort of testing and understanding, building that capacity inside of governments and international institutions, I think is gonna be extremely powerful.
-
And again, we’re all over in these conversations around the world, trying to figure out the ways both to contribute to the technical understanding and formulating these guidelines, the communities that are being built to do this safety work. But again, we just also want to contribute and absorb the research that’s being done, like the work of the Institute. So just look forward to continuing those conversations over time as well. And I guess just sort of curious as you head into the coming months, you mentioned the sort of research work of the Institute, do you have plans around APEC for the ministry or other major moments through the end of the year that sort of stand out for you and the ministry team?
-
Yeah, we’ve advocated in APEC privacy enhancing technologies, specifically zero-knowledge technologies. We’re going to publish domestic guidelines for PETs as well as data altruism organizations by the end of the year. We strongly believe that the DAOs — not that DAO, this DAO — Data Altruism Organizations is the key for interconnected assemblies to share their lived experiences with AI.
-
Because the other metaphor you sometimes hear is the ozone-freon or climate change metaphor. People are polluting the information landscape and we have to think of compounds that does not pollute. That’s where the provenance/watermarking conversation is coming in from that metaphor, but there’s something fundamentally different in that everybody can set up carbon sensors or greenhouse gas sensors or pollution sensors without any permit, right? To emit pollution, you need permit, but to measure, you don’t need permit. But the interactions with language models is fundamentally private, and nobody wants sensors — and censors — all the time, when they have such interactions. So unless it can be done through a trusted intermediary, which maintains contextual integrity and shares in a zero-knowledge way, nobody would want their open-source model and their fine-tunings to be measured in a way that could contribute to the risk sensing.
-
On the other hand, if we don’t democratize this kind of sensing through data altruism organizations, you don’t get the unknown unknowns of the dangers. So I mean, this is something that’s knotty to resolve and probably can only be resolved with global coordination. But I think this is fundamentally essential to get a multi-dimensional view on the elephant, so to speak, right? So this is something that we’re pushing. In addition to APEC, I think the Bletchley Park summit, although quite narrowly focused on agentic slash extinction and widespread misuse, like millions of people die, scenarios, we can also have this kind of social harm or chronic harm measurements designed into the conversation. Because, I mean, there’s a argument that says, climate change kills more people than pandemic, than the coronavirus pandemic, but it’s just more chronic, it’s spread over more years. But at the end of the day, it’s more or less like that, so to speak. And so designing for that sort of harm, I believe, is also quite in line with the AGI view, right, of OpenAI.
-
Yeah, no, and you raised so many important points there, and thinking about sort of the work that I think we’ll all hear much more about coming out of the UK AI Summit and sort of where the research focus goes. And I’ll be very curious to sort of see how some of the discussions of sort of codes of conduct building on the voluntary commitments that many of the labs have already put forward advance there and sort of what comes of them internationally, how different actors around the world take some of that research work, enact it, issue challenges for researchers, for civil society, and how we can carry that work forward into the year ahead. I’m curious if there are other projects that you’ve seen. I know you’ve experimented and done on so many great projects using AI tools. Are there new developments that you’re watching closely or that have you sort of excited or big questions that have come of some of the new developments that you have?
-
I mean, with multimodality, that’s really, really good that you have introduced in such a kind of staggered release, making it comfortable with one community and the next community. Multimodality enables post symbolic communication between communities. The idea, very simply put, is that in a democratic conversation, if it’s face-to-face or high bandwidth AR/VR, and you also worked there, there’s a kind of intimate conversations of tacit understanding that is not symbolic at all, right? It cannot be reduced to signs, either hand signs or symbolic signs. And that is actually why deliberation as a form of democracy works much better than representation or voting, is this tacit, intimate understanding between the jury members, the citizen assembly members, and so on. The thing is that that nuance is completely destroyed when you abstract even just one level away, right? It is impossible to not destroy that nuance when you bring the synthesis documents to the next level, like from the township level to the district level, to the city level and to the global level. So as we have seen time and again, even the local wisdom have found a very nuanced solution that requires like 40 different parameters in the latent space, it gets horribly destroyed into just two lines of headline PowerPoint when you go to the city level.
-
And so I understand that, you know, if everybody does this with, you know, Vision Pro, right, or Quest, or whatever, you can capture some of that, but still it’s a very shallow proxy and you end up having to extrapolate. That is to say, to based on very limited signals and extrapolate, as you have seen in Facebook’s supervisory learning in the newsfeed, has a real danger in that it becomes more persuasive over time.
-
I believe the fundamental error here is to analyze on the unit of an individual. If you aggregate individual signals, no matter how you measure, you lose the plurality that is imbued in community interactions. And so we argue that the smallest unit of alignment assembly should not be an individual. Preferences should be considered on the community level, not individual level.
-
So if we can find out a way to use multi-modal models to compress without losing nuance as a unit of a particular assembly, then it can enable very, very interesting queries. For example, you can join a discussion group after the fact with new information and with new queries and interact with the discussion group and still share in that post symbolic intimacy, this contextual understanding, this mutual understanding and so on. And the group dynamic can be captured as well. And that compression all the way to the top will enable decision makers. Basically, it’s like a glorified scenario theater, right? There’s decision theaters that puts people back to, you know, a situation and then react to that situation in a way that is like more immersive rather than analytical. And so I think decision-making with that is a little bit like, you know, getting all the researchers and decision-makers communicators to play the video game on Steam that’s sponsored by the WHO that talks about the pandemic and finding a cure and things like that, except in even higher fidelity and preserving ever more nuance.
-
Wow, and is there, you know, it got me thinking about sort of in ways that I hadn’t quite spent enough time really thinking about sort of some of the convergence of immersive technologies and sort of the deliberative process. I mean, are there academics or plans in the assemblies to sort of explore some of this more that have come together or, you know, just sort of wondering what the state of sort of the development of just some of the explorations of these questions is out in the world?
-
Yeah, we’re writing a book about that.
-
Amazing!
-
Yeah, with an economist — although he probably describe himself as a pluralist now — Glen Weyl of Microsoft Research and it’s called plurality.net.
-
So if you go to GitHub and search for plurality, that is a more academic way to document such things. And basically, the idea is we want to, over the spectrum of intimacy to wider conversations, to delineate several work domains, basically, from intimate conversations to deliberations and all the way just to voting and things like that, and then push through plurality augmented, LLM augmented, multi-modal augmented, AR/VR augmented ways to push the boundaries all the way. So that is the main idea, but we will document a lot of that in the coming months in plurality.net.
-
Excellent, I can’t wait to read. One plug I’ll just give you – a minute – we just started internally, we’ve started the dialogue. If there are things or developments coming out of OpenAI or work at the Frontier Model Forum or other settings that I can or the team can be helpful with, just please don’t hesitate to reach out anytime. We have our first developer conference coming up in the coming weeks, November 6th.
-
So, you know, as the sort of major updates to functionality, we were just talking about multimodality come out, if there’s any way that, you know, I can follow up or be helpful, you know, if your team has questions, please do let me know there. But you know, we’ll just be curious to continue to follow the work that you’re doing both through the ministry and on the academic side. So I will definitely go and take a look at sort of the published documents on the plurality work so far.
-
Yeah, so I don’t remember whether I’ve sent you the slides we did in the Sunday meeting about certification and evaluation and alignment assembly. If not, let the team follow up on that. We’ve got three advisors of cybersecurity here. And we also want to engage on the linguistic and cultural domain as well. I understand that you’ve been talking with the Taiwanese Junyi Academy. I think that Husan is engaging with them — I don’t know whether Husan is from your team as well? And the idea is that the policy team would like to understand how they can support the Taiwanese culture.
-
I understand you made a deal or at least an agreement with Japan on OpenAI, for the ChatGPT models. These models can speak Japanese just fine, but whether they recognize the Japanese culture or not is another matter altogether. And so I think this kind of cultural tuning, cultural consciousness awareness is on everybody’s mind and in Taiwan it’s even more than that because we’ve got the Taiwanese Taigi which is not Mandarin, we’ve got Holo, we’ve got 16 indigenous nations and 42 language variations and sign language and these are all national languages and so especially with Taigi, with Taiwanese Holo, which most of the elderly people speak more natively than Mandarin, currently if you talk to any of the OpenAI models, it will insist it’s speaking Taiwanese, but actually Cantonese. So it’s likely very minor in the pre-trained model.
-
And we can help. Taiwanese researchers did help Meta on a speech-to-speech Taigi-English translation model that’s on Hugging Face. And I think that’s very powerful. But currently there’s no pipeline to integrate any of those research, either as a pre-filter, a post-filter, a split learning, fine tuning. There’s many ways to do this with the open AI models. And so I’m actually quite curious, because you demonstrated goodwill with Iceland, but pretty much nothing publicly-visible followed after that. So what’s going on?
-
Yeah, I mean, and part of the reason there has been, you know, we’re still trying to figure out, I think the most effective and efficient ways to sort of work on that. We wouldn’t, when we, you know, as we sort of build this pipeline for partnering to improve language performance, which is a major, major priority for us, we just want to make sure we sort of come with the right technical asks. And so, you know, even the work with Iceland, we’ve published a bit on it, but it still continues as we try to figure out what are the right techniques.
-
And we sort of keep coming back, you know, to the different types of data that we’ve tried to work on, different sort of moments in the training process to sort of work back. So I think we are really interested in continuing the conversation, though the place I would say that we, again, are trying to, we don’t quite know yet the most efficient ways to sort of run these linguistic tasks and input scenarios to sort of improve the data, but we absolutely want to sort of figure out a way to partner and do this.
-
And so I think we just probably need, I think for the time being, what we can do is just continue to connect to the teams who are working on this linguistic research inside the company. It may take a little bit of time before we’ve refined exactly the types of asks for, again, for the long tail of language understanding and training, but it’s certainly a priority and definitely can continue to be a point of contact or link the teams who are thinking about this to direct those. And it sounds like some of the conversations have already begun. I haven’t been part of those specifically yet, but happy to connect any of your teams to our researchers internally too.
-
Yeah, yeah. So my conversations with some of your research team members are actually public. So we did talk about that when they visited Taiwan.
-
Oh, great.
-
Yeah. And I think the main thing we’re being asked by our population and constituents and MPs is just whether there’s a benchmark. Can we objectively say that this is the limit of prompt engineering, this is the limit of custom instructions. You really cannot squeeze any more language understanding out of the system prompts basically. So this is what we’re going to do. We’ve, as part of the AIECC, the Evaluation Certificate Center, going to set up by the end of the year, we will have a set of evals, of benchmarks, and through alignment assemblies, we’re going to crowdsource those evaluations. And I understand OpenAI has your own on GitHub, the open evals, so to speak. And I think it’s time that we seriously invest in evals as part of safety. You probably know there’s this figure that there’s 30 capability researchers to every one safety researcher.
-
And although we hear that 20% of compute in OpenAI is going into super alignment, it’s not very visible from the outside… So to seriously increase the investment on democratizing evals, I think that is a touch point that both you and we can make visible progress together because it will not depend on more research breakthroughs on like cross-cultural understanding or whatever other open domains. You will just very simply say that this product emits this much ppm of carbon, basically. You know, this product commits this percent of epistemic injustice, which is fine. I mean, we can own up to it. So we can say, you know, this is the best we have. But it means that when people find out new ways to increase epistemic justice, it gets rewarded in a tangible fashion rather than just one arXiv preprint. That’s my main point.
-
No, that’s really helpful to hear. And, you know, and I think again, this evals work, you’re right in sort of its importance and, you know, going back to where we started on sort of like communities of practice around evals and leading some of this work, providing evals and setting up sort of others throughout the ecosystem to do more of this work and submit them. It’s really exciting to us.
-
And I think it’s really important for sort of getting the next stages of development, right. Maybe the last sort of question on my side, it was just understanding how you and the ministry are sort of thinking about sort of compute, given the chip proficiency there, and if it’s something that is a focus on your side and sort of thinking about future developments on the hardware end, if there are priorities in the ministry or if that is conversations that cut across multiple ministries, but just how you’re thinking about AI compute there at the ministry.
-
Yeah, certainly. So I’ve been running very large language models on my MacBook M2 with 96 gig RAM and it runs even Falcon 180b, sufficiently quantized. So I am a big believer in edge AI. I think without ongoing breakthroughs at homomorphic encryption, other ZK chips, edge AI is the best bet we have. So I think this is a focus that we’re doing In our guidelines for public sector’s use of Gen AI, we believe we’re the only country at the moment that says we ban the use of Gen AI for personal data and confidential data processing, except if you can prove that Edge AI is not connected to the Internet when it’s processing that, and you run through the ISMS, and other cybersecurity arrangements before you do so.
-
So this is a very strong pro-edge AI guideline in our cabinet level guideline for Gen AI use in public sector. And as a direct result, the investment on hardware will increase because then each intranet will have to have its own compute resources for inference and quantized fine-tuning. And I understand that OpenAI is more on the supporting fundamental research with GPT-3 as well as kindly allowing GPT-4 to be distilled way, like this alerted to main touch point for you to engage the local LLM community.
-
I wonder if you want to do more, because obviously you can do more. We heard about plans of a smaller, narrower models being released as open weights on Hugging Face and things like that, but I don’t think anything ever come off from that angle. And I wonder why, whether it’s because open weight models are having a bad reputation from the non-proliferation metaphor or something other than that? Maybe you can illuminate a little bit on that because other frontier labs do release smaller models, like Microsoft does the pi model, right? And textbook model and many other models, not to mention Meta. So what’s the thinking in OpenAI on this?
-
Yeah, that’s a really great question. And one, I think, and coming back to my being ready to come back to you as we even have the major updates that are coming alongside the developer conference, that’s what I’ll have to get back to. Because you’re right that we haven’t really updated publicly on the status of the thinking around providing those types of tools.
-
So I’ll need to get smart on just even the plans coming up in the next few weeks for the developer conference, if there are going to be relevant updates, and just come right back to you and share any of the latest thinking or understanding internally of where we’re going next. So that’s one I’ll be sure to follow up with you.
-
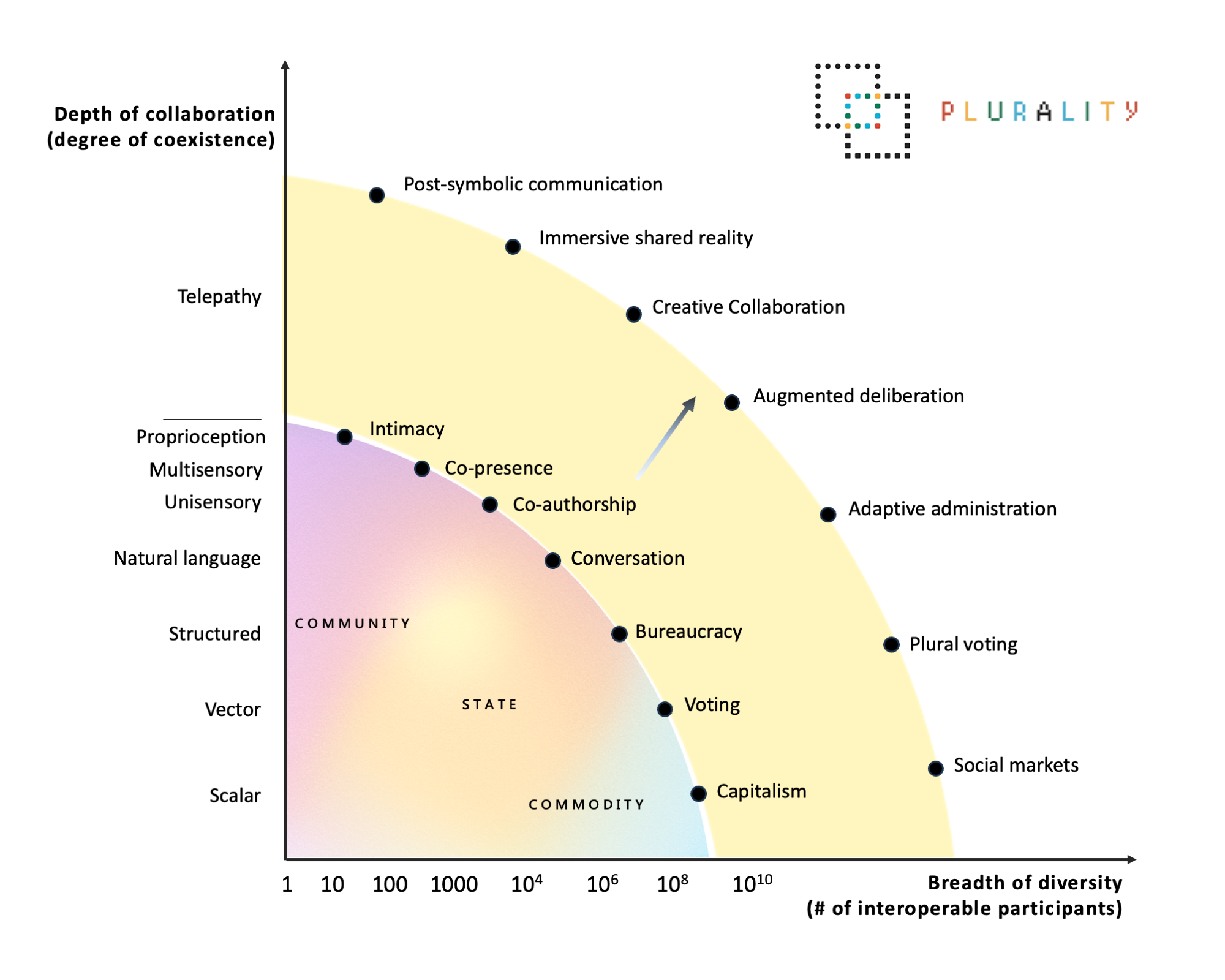
Yeah, I think this actually connects very well to the democratic input that we just talked about. Because the idea is that after alignment assembly, people, a community, a country, or even just a company, can push the boundaries of their own understanding of themselves, basically. So using this plurality diagram, thanks to Glen, it’s about pushing up and to the right. So where it was just conversation, there’s now augmented deliberation, where there was just bureaucracy, there’s now adaptive administration, and so on, which includes more people.
-
I mean, like if you look at augmented deliberation on the middle of the new wave, it’s more intimate than the previous generation’s intimacy and includes more people than capitalism, right? So the idea is to push the boundaries to not make trade-offs. And in this, we can say, after an alignment assembly conversation, we push it a little bit to the plurality side. So the shared context is used to constitutionally align a local AI. Now, whether this local AI is in a partnership API conversation with a larger AI, but just with a local smiley face to the show goes, or whether it’s a full-fledged local model that is being incrementally fine-tuned constitutionally, that is an engineering problem, but a research agenda is very clear: It is having some way to support a use case of local alignment in a way that still contribute back meaningfully to global superalignment.
-
And I understand Sam has been kind of pivoting toward this direction in the past three months. He used to talk about superalignment in a more traditional singularitarian sense. But now I believe he publicly says that he believes that this democratic co-creation is actually the way to go because the threat is super numerous, is multimodal. And so the counter, the alignment need also to be multimodal.
-
And this is really informative. And I can’t wait to sort of see more of the work that comes out, and of course, the book again, because I have so much to learn here. But I’m really excited by the possibilities for this work. So thank you for sharing this.
-
Yeah, excellent. So any questions from our three advisors? Maybe if you’re still around, maybe you can do a quick round of introductions. Any quick questions?
-
Hi, I’m Tom. I’m an advisor at the National Institute of Cybersecurity. I’ve just been absolutely fascinated by this conversation. I don’t think there’s anything I can say that would improve what’s being said. And yeah, very, very much looking forward to what’s happening on both our end and yours.
-
Great, likewise. Well, nice to meet you, Tom. And Gisele, nice to meet you.
-
Hello, nice to meet you, James. Yeah, I’m Gisele. I’m very glad to have this chance to listen, and to describe the book and how we think about the future, because we already have a section discussing digital democracy and how to build up our real relationship to the future.
-
I think that is very important because we are already in the AI times, you know, and we everyday produce so many data. So how we could create good tools for our next generations that is amazing, we need to think about that. So thanks, and nice to meet you.
-
Really nice to meet you too Gisele, thank you.
-
She’s in charge of not just the Mandarin translation of the book, but also a lot of the like conceptual mapping, strategic mapping for the book.
-
I’m excited.
-
Yes, after the meeting, I will send the information and the book domain.
-
Great, I’m looking forward to that. Thank you so much.
-
Okay, right, so on my end, I think the action items, just to very quickly recap, are three, right? We will send materials and double down on our language and epistemic justice evals, and we look forward to hearing from you after the meeting on what’s the latest thinking on that, you know, Iceland and afterwards, right?
-
Second, we will also want to share our democratic input and democratic alignment with you. I understand that the CIP have already worked with OpenAI very successfully, I would say, on the 1,000 people across the US statistically representative, deliberative polling, and that leads to a Zoom conversation, right? That raise many good phenomenological sound points that you cannot get from other quantitative research. So I’m curious to see how you’re engaging the 10 democratic input teams, how to increase the investment to social eval and basically making sure it’s not just a consultation, but rather ends up in something meaningful that the community can use to align themselves.
-
This is a direction I think Anthropic and even Meta is now moving very heavily toward, as you know. So I’m eager to hear what Open Data thinks on this particular direction. And but we’ll continue to run our local alignment assemblies. We run two already and there’s probably three or four coming before end of this year. And it’s all going to be Open Data. So feel free to use it and the process and the toolkits. Anyway, so this is the second thing. And the third thing is about the frontier models, open red teaming, cybersecurity best practices, and whether there’s a credibly neutral entity or a few of those entities. Like NIST or Cybersecurity Institute and so on, we can play a trusted hub like the CVE. Or anything that the frontier models can share the incoming vulnerabilities without compromising trade secrets and confidentiality. This is something I’ve talked at length with the director of NIST and other similar institutes. We all think that even though it requires more expertise than traditional cybersecurity reporting or you know standard setting, it is a worthy investment if we are going to like see a upcoming existential threats six years in the future.
-
Currently, we don’t have that capability in our radar. I think none of us have because these risks only manifest when it touches the society. And so how to make sure that this impact is done in a way with the full forecasting capabilities of the standard-setting bodies and their responsible disclosure in an open-red-teaming way is set up as the bridge across all the frontier models. That is something I think even more than the previous two is going to be absolutely critical all the way to AGI. And so this is something I’m personally very passionate in and I look forward to collaborating with you more on this regard as well.
-
Yes, looking forward to that. An action item on my side as well, I mean in addition to you know we’ll continue to discuss each of those items, the updates on the language work, the democratic inputs, the red teaming, and then I will also just make sure to get you an update on the preparations for the developer day and the major function, whether it’s right at the time that they’re being released, it’s going to be a little bit of time before they’re even finalized still as we head into it, or just after.
-
I’ll be sure to come back to you with a full update and can take any of the questions you have there. But I’m just really grateful to all of you for taking the time to sit down with me today. So just thank you, really appreciate the time, really appreciate the conversation. Can’t wait to read more and learn more and talk soon from here.
-
Okay, thank you. Live long and prosper. Bye for now.
-
Likewise, see you all soon. Bye-bye.
{kind=link}